A classification model designed to predict whether customers will apply for a credit product.
A machine learning project submitted as part of a university analytics module, designed to explore multiple modeling techniques and to conduct an in-depth evaluation and comparison of the resulting models.
This system demonstrates how predictive modeling can support decision-makers in identifying promising credit applicants, while reducing the risk of wasting resources on individuals who are unlikely to be approved for credit.
1.
Business Problem — What Was the Challenge?
A bank wanted to identify which customers were likely to apply for a credit and to understand what factors influenced that decision. With these insights, the bank aimed to proactively engage high-potential customers and reduce the risk of losing them to competitors.
2.
Approach & Method — How It Was Solved
The analysis used an anaonymous dataset that was given to us by the bank. For confidentiality reasons, all variable names were excluded from the dataset, but all recorded observations for the project were present.
Techniques:
- Data cleaning – removal of uninformative variables and missing values
- Proportionality of target variable classes was assessed
- Predictive modeling using logistic regression, support vector machine, random forest, and decision tree
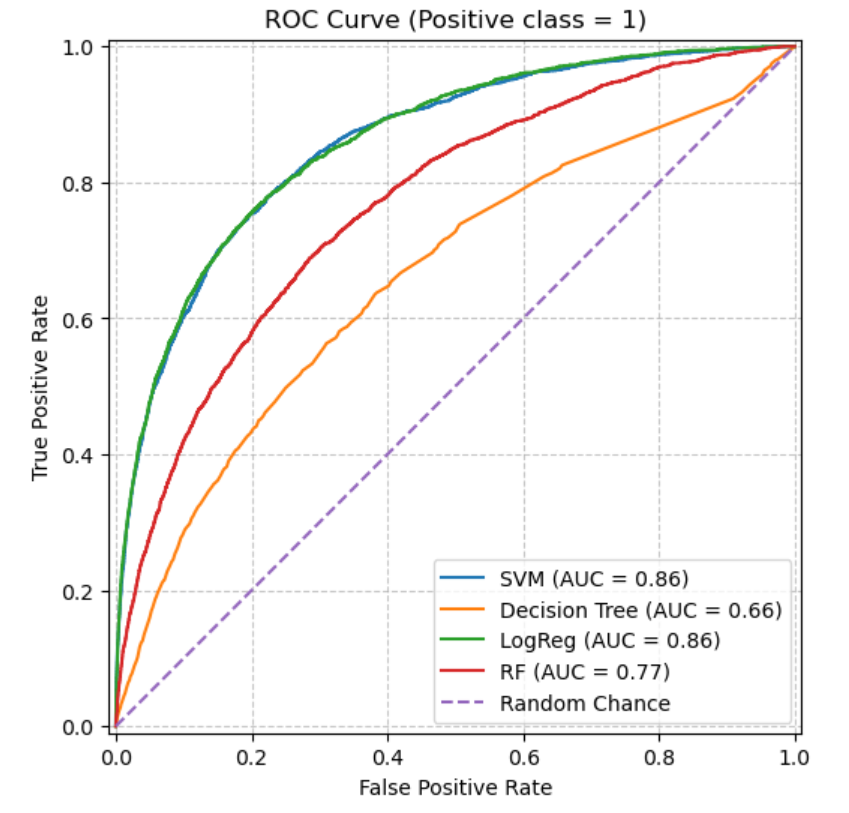
- Model evaluation using accuracy, recall, precision, F1, ROC-AUC, and evaluation graphs
3.
Results & Business Insights
Among all models evaluated, the initial logistic regression achieved the highest recall score. Recall was selected as the primary evaluation metric because correctly identifying customers likely to apply for a credit product (the positive class) was the bank’s main objective. Failing to identify such customers would result in missed opportunities, making false negatives particularly costly.
Although the logistic regression model achieved a recall score of 78%, its precision was comparatively low at 28%. While the model successfully identified many true positive cases, a large proportion of its positive predictions were false positives. In practice, this means the model often classified customers as promising even when they were unlikely to apply for credit.
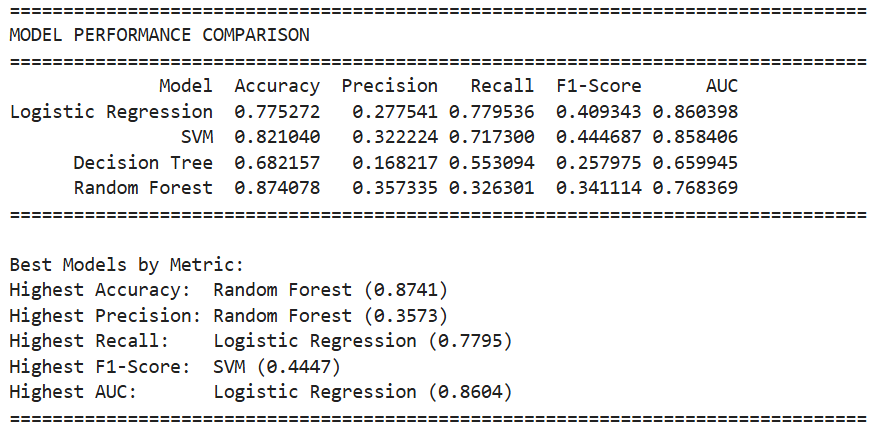
Performance comparison across all models.
4.
Deployment
To reduce the number of false predictions while still capturing the majority of true positives, the model’s classification threshold was tuned using the F1 score. The F1 score balances precision and recall, ensuring that neither false negatives nor false positives dominate the model’s predictions.
The goal was to develop a model that avoids producing excessive false positives, as these would lead the bank to waste resources targeting customers with little or no interest in applying for a credit product.
After threshold tuning, the final logistic regression model achieved a recall score of 52% and a precision score of 48%.
In practice, this model could be implemented in the bank’s customer relationship management department to support decision-making around credit applicants. Predicted approval scores could help relationship managers prioritize high-potential clients, enabling more efficient use of time and resources while maintaining control over credit risk.
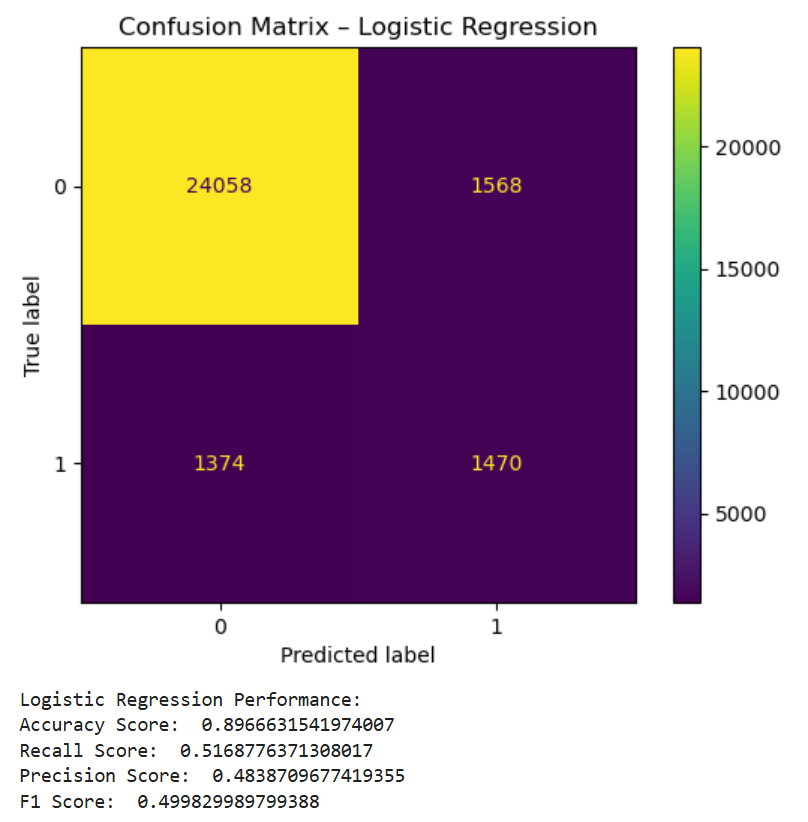
Confusion matrix of the tuned logistic regression model.
5.
Resources
Below you can find a PDF containing all the code used for this project, along with the relevant evaluation graphs.